Apache spark has an advanced DAG execution engine and supports in memory computation. In memory computation combined with DAG execution leads to a far better performance than running map reduce jobs. In this post, I will show an example of using Linear regression with Apache Spark. The dataset is NYC-Yellow taxi dataset for a particular month in 2015. The data was filtered to extract records for a day.
This example uses HiveContext which is an instance of Spark SQL execution engine that integrates with Hive data store. The dataset has the following features.
| Feature Name | Feature Data Type |
|---|
| trip_distance | Double |
| duration (journey_end_time-journey_start_time) | Double |
| store_and_forward_flag(categorical, requires convertion) | String "Y/N" |
| ratecodeid( categorical, requires convertion) | Int |
| start_hour | Int |
| start_minute | Int |
| start_second | Int |
| fare_amount(target variable) | Double |
We want to predict the fare_amount given the set of features. As fare is a continuous variable, so the task of predicting fare requires a regression model.
Things to consider:
- To obtain the data into the dataframe, we must first query the hive store using hiveCtxt.sql() method. We can drop invalid records using na.drop() on the obtained dataframe and then cache it usingcache() method for later use.
- The two categorical variables need to be converted to vector representation. This is done by usingStringIndexer and OneHotEncoder. Look at the method preprocessFeatures() in the code below.
- Models can be saved by serializing them as sc.parallelize(Seq(model),1).saveAsObjectFile("nycyellow.model") and can be used by deserializing themsc.objectFile[CrossValidatorModel]("nycyellow.model").first(). Newer spark api supports OOTB methods for doing this and using those methods is recommended.
- Data can be split into training and testing data by using randomSplit() method on the DataFrame. Although if you are using cross validation, it is recommended to train the model on the entire sample dataset.
- The features in the dataframe must be transformed using VectorAssembler into the vector representation and the column should be named as features. The target variable should be renamed as label, you can use withColumnRenamed() function to do so.
- Cross validation can be performed using CrossValidatorModel and estimator can be set bysetEstimator().
- The evaluator chosen depends on whether you are doing classification or regression. In this case, we would use RegressionEvaluator
- You can specify different values for parameters such as regularization parameter, number of iterations and those would be used by CrossValidatorModel to come up with the best set of parameters for your model.
- After this you can fit the model with the dataset and evaluate its performance. In this case, as we are testing regression model accuracy. We can use RegressionMetrics to compare the predicted_fare vs actual_fare. The measures that can be used are R-Squared (r2), Mean Absolute Error.
- For new predictions the saved model can be reused. The new data needs to be transformed into the same format as was used to train the model. To do so we must first create a dataframe usingStructType to specify its structure, then preprocess features the same way by invokingpreprocessFeatures() method.
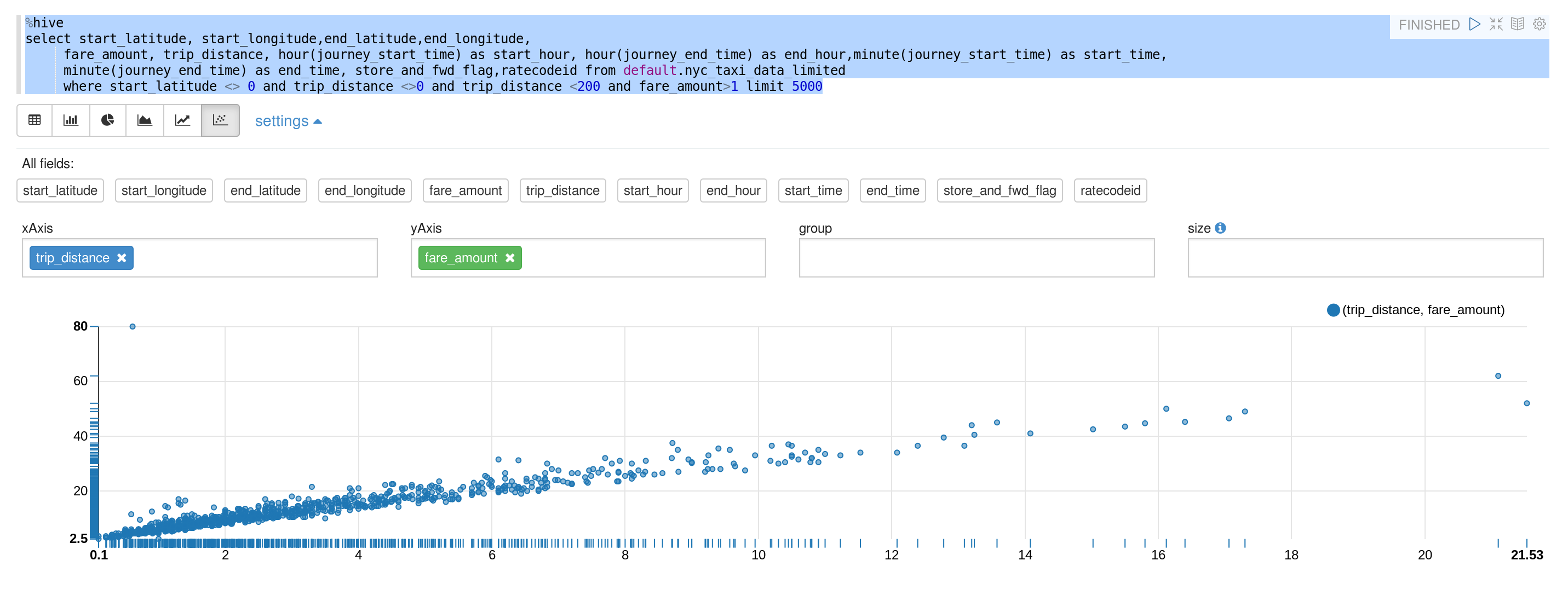
- The data can be visualized using Apache Zeppelin .
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.DataFrame
import org.apache.spark.ml.PipelineStage
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.feature.OneHotEncoder
import org.apache.spark.mllib.regression.LinearRegressionWithSGD
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.{ Vector, Vectors }
import org.apache.spark.sql.Row;
import org.apache.spark.ml.tuning.CrossValidator
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.regression.LinearRegression
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
import org.apache.spark.mllib.evaluation.RegressionMetrics
import org.apache.spark.ml.tuning.ParamGridBuilder
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.types.StructField
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.types.DoubleType
import org.apache.spark.sql.types.StructType
import org.apache.spark.ml.evaluation.RegressionEvaluator
import akka.dispatch.Foreach
import org.apache.spark.sql.DataFrame
import org.apache.spark.ml.PipelineModel
import org.apache.hadoop.mapred.InvalidInputException
import org.apache.spark.ml.regression.LinearRegressionModel
import org.apache.spark.ml.tuning.CrossValidatorModel
import scala.collection.mutable.ListBuffer
import edu.nyu.realtimebd.analytics.nyctaxi.domain.NYCDomain.NYCParams
import org.apache.spark.sql.types.IntegerType
/*
*@Author Ramandeep Singh
*/
object Analytics {
val sparkConf = new SparkConf().setAppName("NYC-TAXI-ANALYSIS").setMaster("local")
val sc = new SparkContext(sparkConf)
val sqlContext = new SQLContext(sc)
val hiveCtxt = new HiveContext(sc)
var df: DataFrame = _
def initializeDataFrame(query: String): DataFrame = {
//cache the dataframe
if (df == null) {
df = hiveCtxt.sql(query).na.drop().cache()
}
return df
}
def preprocessFeatures(df: DataFrame): DataFrame = {
val stringColumns = Array("store_and_fwd_flag", "ratecodeid")
var indexModel: PipelineModel = null;
var oneHotModel: PipelineModel = null;
try {
indexModel = sc.objectFile[PipelineModel]("nycyellow.model.indexModel").first()
} catch {
case e: InvalidInputException => println()
}
if (indexModel == null) {
val stringIndexTransformer: Array[PipelineStage] = stringColumns.map(
cname => new StringIndexer().setInputCol(cname).setOutputCol(s"${cname}_index"))
val indexedPipeline = new Pipeline().setStages(stringIndexTransformer)
indexModel = indexedPipeline.fit(df)
sc.parallelize(Seq(indexModel), 1).saveAsObjectFile("nycyellow.model.indexModel")
}
var df_indexed = indexModel.transform(df)
stringColumns.foreach { x => df_indexed = df_indexed.drop(x) }
val indexedColumns = df_indexed.columns.filter(colName => colName.contains("_index"))
val oneHotEncodedColumns = indexedColumns
try {
oneHotModel = sc.objectFile[PipelineModel]("nycyellow.model.onehot").first()
} catch {
case e: InvalidInputException => println()
}
if (oneHotModel == null) {
val oneHotTransformer: Array[PipelineStage] = oneHotEncodedColumns.map { cname =>
new OneHotEncoder().
setInputCol(cname).setOutputCol(s"${cname}_vect")
}
val oneHotPipeline = new Pipeline().setStages(oneHotTransformer)
oneHotModel = oneHotPipeline.fit(df_indexed)
sc.parallelize(Seq(oneHotModel), 1).saveAsObjectFile("nycyellow.model.onehot")
}
df_indexed = oneHotModel.transform(df_indexed)
indexedColumns.foreach { colName => df_indexed = df_indexed.drop(colName) }
df_indexed
}
def buildPriceAnalysisModel(query: String) {
initializeDataFrame(query)
var df_indexed = preprocessFeatures(df)
df_indexed.columns.foreach(x => println("Preprocessed Columns Model Training" + x))
val df_splitData: Array[DataFrame] = df_indexed.randomSplit(Array(0.7, 0.3), 11l)
val trainData = df_splitData(0)
val testData = df_splitData(1)
//drop target variable
val testData_x = testData.drop("fare_amount")
val testData_y = testData.select("fare_amount")
val columnsToTransform = trainData.drop("fare_amount").columns
//Make feature vector
val vectorAssembler = new VectorAssembler().
setInputCols(columnsToTransform).setOutputCol("features")
columnsToTransform.foreach { x => println(x) }
val trainDataTemp = vectorAssembler.transform(trainData).withColumnRenamed("fare_amount", "label")
val testDataTemp = vectorAssembler.transform(testData_x)
val trainDataFin = trainDataTemp.select("features", "label")
val testDataFin = testDataTemp.select("features")
val linearRegression = new LinearRegression()
trainDataFin.columns.foreach(x => println("Final Column =>" + x))
trainDataFin.take(1)
//Params for tuning the model.
val paramGridMap = new ParamGridBuilder()
.addGrid(linearRegression.maxIter, Array(10, 100, 1000))
.addGrid(linearRegression.regParam, Array(0.1, 0.01, 0.001, 1, 10)).build()
//5 fold cross validation
val cv = new CrossValidator().setEstimator(linearRegression).
setEvaluator(new RegressionEvaluator()).setEstimatorParamMaps(paramGridMap).setNumFolds(5)
//Fit the model
val model = cv.fit(trainDataFin)
val modelResult = model.transform(testDataFin)
val predictionAndLabels = modelResult.map(r => r.getAs[Double]("prediction")).zip(testData_y.map(R => R.getAs[Double](0)))
val regressionMetrics = new RegressionMetrics(predictionAndLabels)
//Print the results
println(s"R-Squared= ${regressionMetrics.r2}")
println(s"Explained Variance=${regressionMetrics.explainedVariance}")
println(s"MAE= ${regressionMetrics.meanAbsoluteError}")
val lrModel = model.bestModel.asInstanceOf[LinearRegressionModel]
println(lrModel.explainParams())
println(lrModel.weights)
sc.parallelize(Seq(model), 1).saveAsObjectFile("nycyellow.model")
}
def predictFare(list: ListBuffer[NYCParams]): DataFrame = {
var nycModel: CrossValidatorModel = null;
try {
nycModel = sc.objectFile[CrossValidatorModel]("nycyellow.model").first()
} catch {
case e: InvalidInputException => println()
}
if (nycModel == null) {
buildPriceAnalysisModel("""select
trip_distance,
(cast(journey_end_time as double)-cast(journey_start_time as double)) as duration,
store_and_fwd_flag,
ratecodeid,
hour(journey_start_time) as start_hour,
minute(journey_start_time) as start_minute,
second(journey_start_time) as start_second,
fare_amount from nyc_taxi_data_limited
where start_latitude <> 0 and trip_distance >0
and journey_end_time>journey_start_time and
trip_distance <200 and fare_amount>1 limit 12000""")
}
nycModel = sc.objectFile[CrossValidatorModel]("nycyellow.model").first()
var schema = StructType(Array(
StructField("trip_distance", DoubleType, true),
StructField("duration", DoubleType, true),
StructField("store_and_fwd_flag", StringType, true),
StructField("ratecodeid", DoubleType, true),
StructField("start_hour", IntegerType, true),
StructField("start_minute", IntegerType, true),
StructField("start_second", IntegerType, true)))
var rows: ListBuffer[Row] = new ListBuffer
list.foreach(x => rows += Row(x.trip_distance, x.duration, x.store_and_fwd_flag, x.ratecodeid, x.start_hour, x.start_minute, x.start_second))
val row = sc.parallelize(rows)
var dfStructure = sqlContext.createDataFrame(row, schema)
var preprocessed = preprocessFeatures(dfStructure)
preprocessed.columns.foreach(x => println("Preprocessed Columns " + x))
val vectorAssembler = new VectorAssembler().
setInputCols(preprocessed.columns).setOutputCol("features")
preprocessed = vectorAssembler.transform(preprocessed)
var results = nycModel.transform(preprocessed.select("features"))
results
}
}
Results
Upon training the model, it gave the following results against the test data set.
R-Squared= 0.954496421456682
MAE= 1.1704343793855545
To predict the fares for our inputs we can invoke predictFare() method. Example code to do so is mentioned below.
After the initial invocation all the models are stored in the directory from which the execution is carried out.
For the sample request above the result is shown below.
This prediction shows that the journey for 10.6 miles, if covered in 10 minutes, by using NYC yellow taxi would cost roughly 31 dollars.