








If you are working with Spark, you will most likely have to write transforms on dataframes. Dataframe exposes the obvious method df.withColumn(col_name,col_expression) for adding a column with a specified expression. Now, as we know that the dataframes are immutable in nature, so we are getting a newly created copy of dataframe with our added column (if you look at the source code for method withColumn, you will also see additional checks being performed, like whether the column exists or not. That check is unnecessary in most cases). And, this is very inefficient, especially, if we have to add multiple columns. for example, a wide transform of our dataframe such as pivot transform (Note: There is also a bug [1] on how wide your transformation can be, which is fixed in Spark 2.3.0).
Here is an optimized version of a pivot method. Note that rather than using df.withColumn, we are collecting all column expressions in a mutable ListBuffer and then applying all expressions at once via df.select(colExprs: _*)which is phenomenally fast, especially considering the fact that df.withColumn hangs the driver process even for a transform on a few hundred columns(it causes hung threads and locks, you can see this using jVisualVM), whereas the optimized version can operate on thousands of columns easily.
Optimized Version:
/**
* Pivots the DataFrame by the pivot column. It is better to specify the distinct values, as otherwise distinct values need to be calculated
*
* @param groupBy The columns to groupBy
* @param pivot The pivot column
* @param distinct An Optional Array of distinct values
* @param agg the aggregate function to apply. Default="sum"
* @param df the df to transpose and return
* @param ev the implicit encoder to use
* @tparam A The type of pivot column
* @return the transposed dataframe
*/
def doPivotTF[A](groupBy: Seq[String], pivot: String, distinct: Option[Array[A]], agg: String = "sum")(df: Dataset[Row])(implicit ev: Encoder[A]): Dataset[Row] = {
val colsToFilter = (Seq(pivot) ++ groupBy ++ df.schema.filter(_.dataType match {
case _: NumericType => false
case _: Numeric[_] => false
case _ => true
}).map(_.name)).distinct
val colsToTranspose = df.columns.filter(!colsToFilter.contains(_)).toSeq
if (logger.isDebugEnabled) {
logger.debug(s"colsToFilter $colsToFilter")
logger.debug(s"colsToTranspose $colsToTranspose")
}
val distinctValues = distinct match {
case Some(v) => v
case None => {
df.select(col(pivot)).map(row => row.getAs[A](pivot)).distinct().collect()
}
}
val colExprs = new ListBuffer[Column]()
colExprs += col("*")
for (colName <- span=""> colsToTranspose) {
for (index <- span=""> distinctValues) {
val colExpr = when(col(pivot) === index, col(colName)).otherwise(0.0)
val colNameToUse = s"${colName}_TN$index"
colExprs += colExpr as colNameToUse
}
}
val transposedDF = df.select(colExprs: _*)
//Drop all original columns except columns in groupBy
val colsToDrop = colsToFilter.filter(!groupBy.contains(_)) ++ colsToTranspose
val dfBeforeGroupBy = transposedDF.drop(colsToDrop: _*)
val finalDF = dfBeforeGroupBy.groupBy(groupBy.map(col): _*).agg(dfBeforeGroupBy.columns.filter(!groupBy.contains(_)).map(_ -> agg).toMap)
//Remove spark generated $agg suffixes
val finalColNames = finalDF.columns.map(_.stripSuffix(s"$agg(").stripSuffix(")"))
if (logger.isDebugEnabled()) {
logger.debug(s"Final set of colum names $finalColNames")
}
finalDF.toDF(finalColNames: _*)
}
Slow Version:
/**
* Pivots the DataFrame by the pivot column. It is better to specify the distinct values, as otherwise distinct values need to be calculated
*
* @param groupBy The columns to groupBy
* @param pivot The pivot column
* @param distinct An Optional Array of distinct values
* @param agg the aggregate function to apply. Default="sum"
* @param df the df to transpose and return
* @param ev the implicit encoder to use
* @tparam A The type of pivot column
* @return the transposed dataframe
*/
def doPivotTFSlow[A](groupBy: Seq[String], pivot: String, distinct: Option[Array[A]], agg: String = "sum")(df: Dataset[Row])(implicit ev: Encoder[A]): Dataset[Row] = {
val colsToFilter = (Seq(pivot) ++ groupBy ++ df.schema.filter(_.dataType match {
case _: NumericType => false
case _: Numeric[_] => false
case _ => true
}).map(_.name)).distinct
val colsToTranspose = df.columns.filter(!colsToFilter.contains(_)).toSeq
if (logger.isDebugEnabled) {
logger.debug(s"colsToFilter $colsToFilter")
logger.debug(s"colsToTranspose $colsToTranspose")
}
val distinctValues: Array[A] = distinct match {
case Some(v) => v
case None => df.select(col(pivot)).distinct().map(_.getAs[A](pivot)).collect()
}
var dfTemp = df
for (colName <- span=""> colsToTranspose) {
for (index <- span=""> distinctValues) {
val colExpr = when(col(pivot) === index, col(colName)).otherwise(0.0)
val colNameToUse = s"${colName}_TN$index"
dfTemp = dfTemp.withColumn(colNameToUse, colExpr)
}
}
val transposedDF = dfTemp
//Drop all original columns except columns in groupBy
val colsToDrop = colsToFilter.filter(!groupBy.contains(_)) ++ colsToTranspose
val dfBeforeGroupBy = transposedDF.drop(colsToDrop: _*)
val finalDF = dfBeforeGroupBy.groupBy(groupBy.map(col): _*).agg(dfBeforeGroupBy.columns.filter(!groupBy.contains(_)).map(_ -> agg).toMap)
//Remove spark generated $agg suffixes
val finalColNames = finalDF.columns.map(_.stripSuffix(s"$agg(").stripSuffix(")"))
if (logger.isDebugEnabled()) {
logger.debug(s"Final set of colum names $finalColNames")
}
finalDF.toDF(finalColNames: _*)
}
VisualVM Image
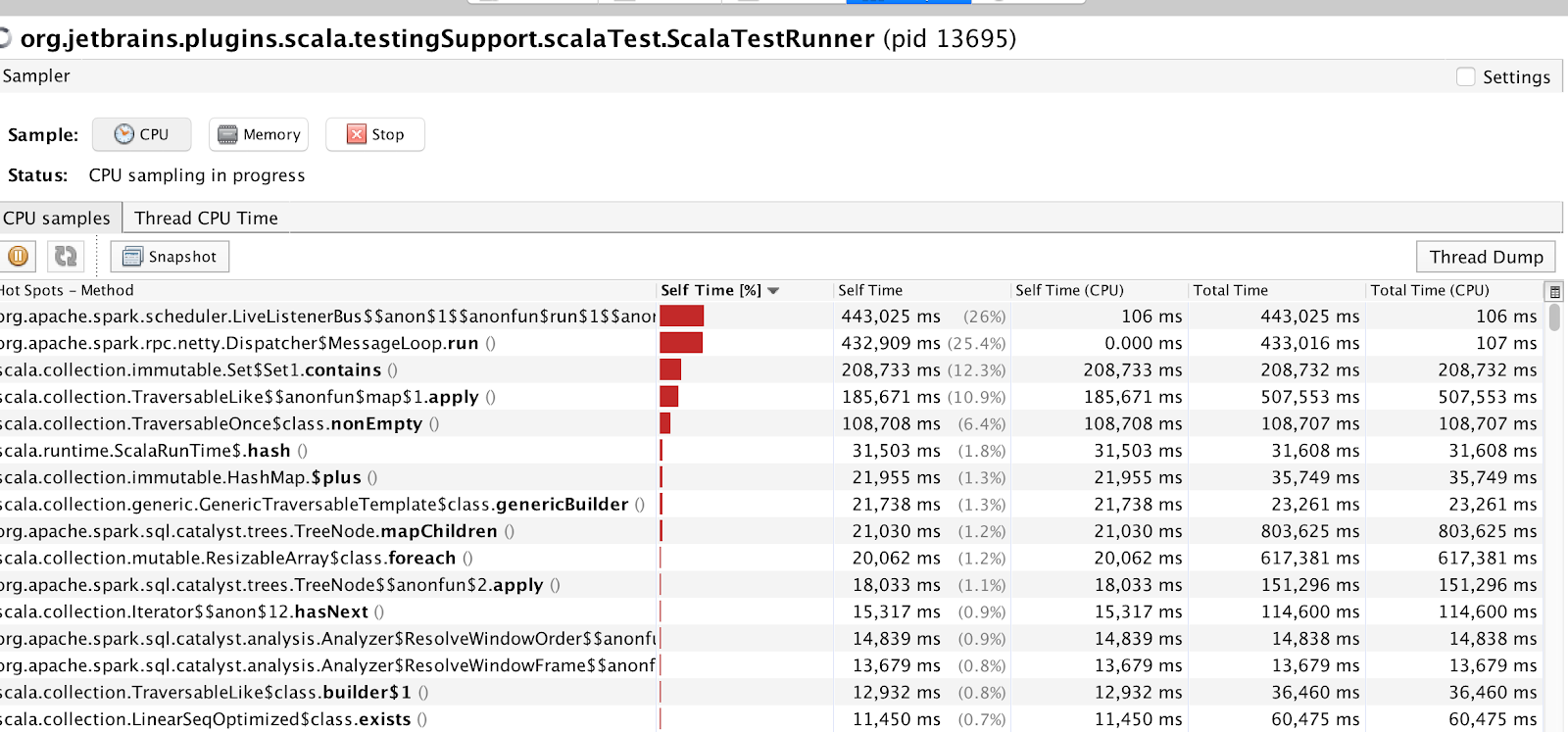
So the crux here is always use df.select rather than df.withColumn, unless you are sure that the transform is only going to be invoked on a few columns.
| [1] | https://issues.apache.org/jira/browse/SPARK-18016 |



